Applying GENEVE encapsulation (flow hashing, VPC<->VPC NAT)
This post is going to be about one of the technologies that powers networking at AWS: an application of Geneve encapsulation to do VPC to VPC NAT, or how you get packets from an ENI in one VPC to an ENI in another VPC.
This post describes the encapsulation that is used and explains some of the motivations and a blurb on flow hashing.
What is the networking stack
When you hear the “networking stack” you need understand it in terms of layers of abstraction that build on top of each other. At the lowest level you have physical data transmission, the next level you have ethernet frames (data link), the next level contains IP frames (network layer) and then finally a TCP or UDP frame. Colloquially we just refer to these as layers 1-4.
One way to understand the usefulness of the networking stack is in terms of what constraints you have: when you go up the networking stack you have less constraints. TCP on the transport layer enforces a socket per connection and has strict ordering rules, but when you get to layer 3 (IP aka TUN layer) you can inspect TCP, as well as UDP packets, as well as everything else (eg ICMP packets).
To oversimplify, understanding these layers is important for understanding how you can process packets quickly for something like sending packets from one partition/network to another, because intuitively you need additional layers to store meaningful routing metadata.
Geneve encapsulation
RFC 8926 describes Geneve encapsulation.
Geneve encapsulation is most relevant from sections 3.1 to 3.3. From a technical perspective the main thing you need to know to understand GENEVE is the following: it exists as a layer 4 (transport layer) UDP way of encapsulating layer 2 - layer 4 information for network virtualization. So you can send these GENEVE encapsulated packets using a user space socket but it communicates a lot more information because it has both an inner and outer packet frame. The inner frame can contain an entire ethernet frame which can be intercepted by a TUN/TAP device running on a different machine (a NIC). Any time you have a need to do network virtualization it is most likely you would have to use GENEVE encapsulation as it is the standard (supercedes VXLAN).

The included figure of GENEVE on IPv4 shows that your payload can be anything you want it to be or what the receiver expects. If you’re encapsulating a regular TCP packet you would just write the IPv4 header and TCP frame here.
Importantly the details of how these packets are used are up to the network you’re connecting to
Since GENEVE operates within the context of UDP it has a natural analogue to the connectionless semantics of Ethernet and IP which is why it lends itself so well to be used to directly pipe in data from a TUN device (as opposed to something like TCP).
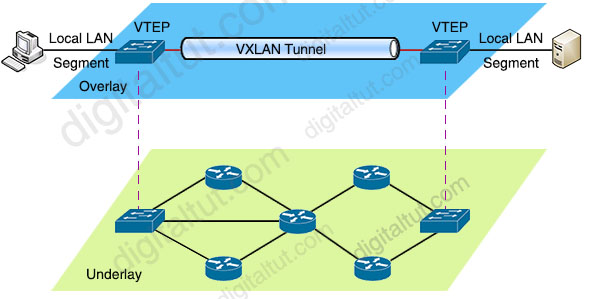
GENEVE encapsulation is super important whenever you want to build networks (overlay networks) on top of another network (an underlay) which is why it’s widely adopted among cloud computing companies. They have the raw hardware (underlay) and the overlay (to oversimplify a bit) is the virtualized network that they create for you (eg a VPC with subnets). The following section will describe this in more detail
Real world application with flow hashing
A lot of the time you’ll have to deal with some form of encapsulation during which there’s a network boundary transition. I dealt with this on my team where our traffic transitions the network boundary from our service VPC (IPv6) into a customer VPC (IPv4). A large part of our service offering is tunneling traffic into customer’s VPCs.
In this case the outer packet was IPv6 going over UDP and the inner (GENEVE encapsulated) packet was IPv4.
This meant that any reverse traffic was always IPv4 and had to be translated to IPv6 to be sent back to the originating client.
You cannot simply encode the client’s IPv6 address in an IPv4 space because it won’t fit, so instead you have to perform translation by hashing the originating flow 5-tuple, mapping this to an IPv6 address and use this information to map back onto the originating flow for reverse traffic.
For example, if your service operates in an IPv6 space, that is to say every client that ingresses to your service sends it with an IPv6 header and you want to egress this traffic to a machine that operates exclusively in IPv4 space (over GENEVE or not) this becomes a significant hurdle. On the ingress path for return traffic you must identify the correct forward initiating IPv6 flow from an IPv4 packet, and are forced to store additional information (state) to identify originating flows for reverse traffic. This can get quite complicated the more flows you have, or if your system is multi tenant, and it has to be done per packet without degrading performance. Additionally, since flow hashing is generally the way we identify what flows are which, we have to make sure that whatever form of hashing that is being used is resistant to collisions and/or have adequate solutions for dealing with them. This is a real problem that services have to solve when sending traffic from one machine to another when transitioning over network boundaries.
Flow hashing isn’t perfect and definitely has some tradeoffs, including handling cache misses/latency, but if you constrain the number of flows your system can support and have a large enough hash space all of these problems are solvable.
Conclusion
This post was brief but something that I felt was necessary to capture as I haven’t found any other articles about it online.
Thanks for reading!
Back