Porting disk intensive Kubernetes services to AWS Lambda
Recently I was working on porting a terraform drift detector to AWS Lambda. This is a service I developed a while back, still is in use today and has been responsible for preventing incidents due to unmerged/unapplied infrastructure in terraform.
I would like to write about the main constraint I encountered trying to accomplish this and how this constraint can be circumvented around while porting this service to Lambda.
Context
The short and simple of it is that the drift detector just clones a bunch of repositories, finds all of its terraform directories with some tree searching, and then invokes terraform plan a bunch (after doing some massaging of some module paths) to figure out whether or not that service has drift.
This service is really interesting from a technical perspective because there’s some cool things it does to get this work since
- it doesn’t actually use the git cli to clone repos (it does super shallow cloning using the GHE api and only gets
terraformdirectories) - it rewrites custom terraform module URIs that go over HTTPs/ssh unauthed by rewriting them to strictly HTTPs ones with your personal access token, to allow you to pull modules from other internal repos
Before moving it to lambda the drift detector was running in an EKS cluster and doing perfectly fine until it eventually would consume all of the disk on the node it was scheduled on. It was only ran as a single pod in our cluster and would result in a lot of disk pressure errors, eventually resulting in a whole node being evicted from the cluster which would trigger a variety of fun alarms that were hard to diagnose.
It’s not clear exactly why there was a disk resourcing issue with the service and I even tried limiting its ability to write to a limited-capacity Kubernetes volume but it didn’t resolve the issue :). My guess is terraform commands generate artifacts that aren’t being cleaned up, possibly something related to plugins.
Either way, in the meantime the problem would be solved if we just moved the service to lambda. The other reason besides the node evictions was that it would be part of a wider initiative to reduce the number of services running in our legacy EKS infrastructure which we were offboarding. Fixing the disk leak in the first place would’ve been a great solution too, but it was proving more difficult than simply porting it to lambda. Plus, even if we fixed the disk issue we couldn’t guarantee that it simply wouldn’t re-emerge or have to write a lot of code that did manual cleaning.
Porting the drift detector to lambda
Since the drift detector was designed to run as a Go service in a docker container and use all of the binaries in that container (terraform, tfenv (for terraform versioning) and git) it made the most sense to use AWS Lambda with ECR for containerization. Previously the service had been running in an EKS cluster.
The setup for this change was pretty simple. All that was necessary was to stand up an ECR repo, set up a build process script (or whatever you prefer) for building the main service binary locally, then create a Dockerfile that pulls that locally built binary and once the image is build pushes it to ECR so that the image can execute that binary.
The only real “gotcha” here is that you have to make sure you are configuring the lambda’s network configuration properly, host machine (in this case x86_64 which is amd64, aka not ARM) and that it has enough disk space/memory and you should be good to go.
The vast majority of the source code could stay the same but with minor modifications to some of the alarms (we can use the cloudwatch lambda invocation metric as a heartbeat check as opposed to emitting one ourselves like before).
Difficulty arose whenever I tried to actually get binaries to run on the machine. The AWS documentation isn’t great about this but the only writable directory on a dockerized lambda is /tmp. This becomes an issue when you run a binary and it stores local data in the current working directory of where the binary is, or /usr/local/bin on amazonlinux with a lambda function.
It turns out that tfenv writes its current version state in $PATH/tfenv/version which isn’t writable if it’s not in /tmp so you have to make sure that your tfenv is installed with respect to /tmp.
You also can’t just move everything on container launch to /tmp and point the $PATH to /tmp–it won’t work because /tmp is an ephemeral volume that only gets mounted when the lambda container loads.
The solution for this ends up to be setting an environment variable called TFENV_CONFIG_DIR to /tmp/tfenv/ so that tfenv thinks its going to configure itself in /tmp.
Fortunately, this workaround was very simple.
Conclusion
So that’s how I ended up getting everything working on lambda as it did before despite the constraint that /tmp is the only writable volume in a lambda container.
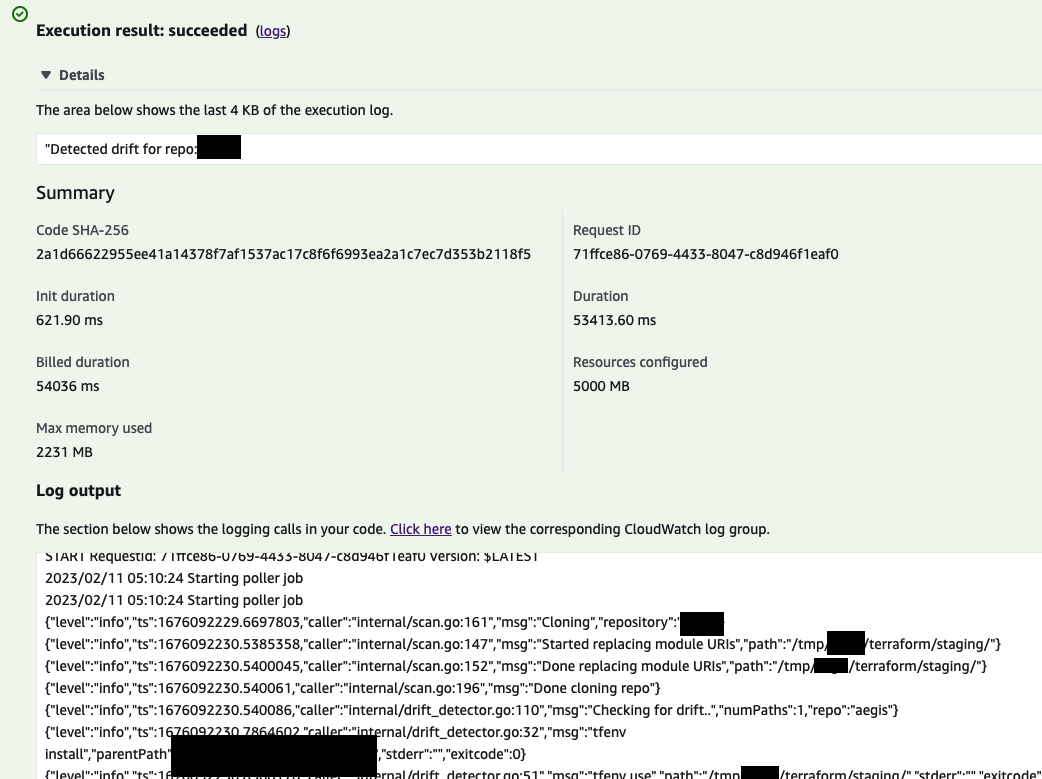
After invoking the lambda with the repository name and setting up EventBridge to invoke it repeatedly everything works just as before. The only other thing that is notable is that EventBridge rules are limited to at most 5 target per rule, so if you have more than 5 repos you need to keep that in mind (I ended up making 1 rule per repo).

After deploying the lambda our graphs started to look a lot healthier, specifically the disk usage and the number of node evictions. The disk usage dropped to from 80% to 60% and the number of evictions to 0.
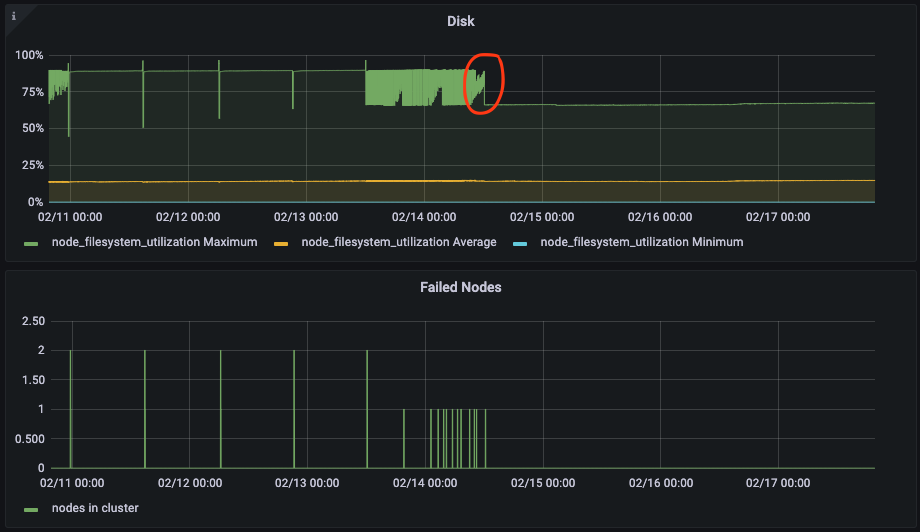
I was happy with this result. Since making this change on-call has been a lot less noisy and we’ve seen less alarms go off overall which is a result of having zero node evictions.
Back