Reaching near-perfect accuracy for fish pool detection
Since the last post I added 3,000 more images to my training set and changed the model to be a lot like ResNet with skip connections and the removal of dropout between convolutions entirely. I also downscaled the input by 50%, so it’s 25% of what it is at a native resolution which speeds it up significantly while running. Finally, I modified the training algorithm to be evaluated on the test set after only 10 epochs then saved to disk with its evaluation score. After 3 hours of training the model achieves IOU = 0.87 on a test set of 500 images that it was not trained on. This corresponds to an MSE loss of ~5 (99.4% accurate).
In my last post on average the IOU score was 60% (80% overlap only achieved on the training set). This new model actually achieves an 87% overlap in general and in practice!
To give you a good idea of how amazing this is, below is an example of what an IOU metric of 0.92 looks like. 0.87 is not so far off and from what I could tell my model was effectively perfect.
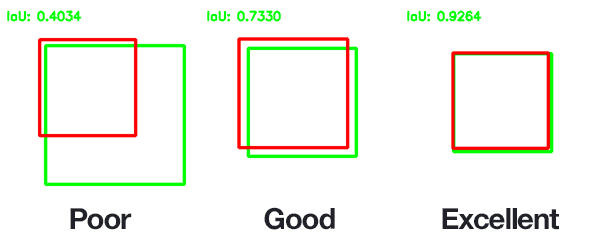
Considering that my test size was so large (n = 500) an average score of 0.87 is great.
Demonstration
Below is a video I recorded with OBS while running the AI in the background on live screen data.
Keras Model
Below is the code for the Keras model that features skip connections and a much deeper network structure.
inputs = Input(shape=(input_size[1],input_size[0],3,))
x = Conv2D(64, kernel_size=7, padding='same', activation='relu')(inputs)
y = MaxPooling2D(pool_size=(2, 2))(x)
x = Conv2D(64, kernel_size=3, padding='same', activation='relu')(y)
x = BatchNormalization()(x)
x = Conv2D(64, kernel_size=3, padding='same', activation='relu')(x)
z = Add()([x, y])
y = MaxPooling2D(pool_size=(2, 2))(z)
x = Conv2D(64, kernel_size=3, padding='same', activation='relu')(y)
x = BatchNormalization()(x)
x = Conv2D(64, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
x = MaxPooling2D(pool_size=(2, 2))(z)
x = BatchNormalization()(x)
y = Conv2D(128, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(y)
x = Conv2D(128, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
y = Conv2D(128, kernel_size=3, padding='same', activation='relu')(z)
x = BatchNormalization()(y)
x = Conv2D(128, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
x = MaxPooling2D(pool_size=(2, 2))(z)
x = BatchNormalization()(x)
y = Conv2D(256, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(y)
x = Conv2D(256, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
y = Conv2D(256, kernel_size=3, padding='same', activation='relu')(z)
x = BatchNormalization()(y)
x = Conv2D(256, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
y = Conv2D(256, kernel_size=3, padding='same', activation='relu')(z)
x = BatchNormalization()(y)
x = Conv2D(256, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
y = Conv2D(256, kernel_size=3, padding='same', activation='relu')(z)
x = BatchNormalization()(y)
x = Conv2D(256, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
x = MaxPooling2D(pool_size=(2, 2))(z)
z = BatchNormalization()(x)
y = Conv2D(512, kernel_size=3, padding='same', activation='relu')(z)
x = BatchNormalization()(y)
x = Conv2D(512, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
y = Conv2D(512, kernel_size=3, padding='same', activation='relu')(z)
x = BatchNormalization()(y)
x = Conv2D(512, kernel_size=3, padding='same', activation='relu')(x)
x = BatchNormalization()(x)
z = Add()([x, y])
x = MaxPooling2D(pool_size=(2, 2))(z)
x = BatchNormalization()(x)
x = Flatten()(x)
x = Dropout(0.5)(x)
coords = Dense(4, activation='linear')(x)
Making the network shallower really helped, since I noticed that when it was running with 5 more convolutional layers it bottlenecked at IOU = 0.6 then dipped immediately down in generalization to IOU = 0.01 (basically zero generalization). It was really amazing to see the results when I removed a few layers and lowered the learning rate to the default for the adam optimizer, since it started outperforming the old model immediately.
Training results with flipped images
Below is an example of what happens when I introduce a horizontal flipping to the dataset (how fast the model trains from start to finish)
Epoch 1/10
9528/9528 [==============================] - 39s 4ms/step - loss: 552.3671 - acc: 0.9447 - iou_metric: 0.3699
Epoch 2/10
9528/9528 [==============================] - 33s 3ms/step - loss: 35.7350 - acc: 0.9856 - iou_metric: 0.6153
Epoch 3/10
9528/9528 [==============================] - 33s 3ms/step - loss: 19.7822 - acc: 0.9875 - iou_metric: 0.6835
Epoch 4/10
9528/9528 [==============================] - 32s 3ms/step - loss: 15.1078 - acc: 0.9912 - iou_metric: 0.7110
Epoch 5/10
9528/9528 [==============================] - 32s 3ms/step - loss: 10.3590 - acc: 0.9920 - iou_metric: 0.7439
Epoch 6/10
9528/9528 [==============================] - 33s 3ms/step - loss: 8.3490 - acc: 0.9928 - iou_metric: 0.7591
Epoch 7/10
9528/9528 [==============================] - 34s 4ms/step - loss: 6.7133 - acc: 0.9934 - iou_metric: 0.7789
Epoch 8/10
9528/9528 [==============================] - 34s 4ms/step - loss: 5.1931 - acc: 0.9948 - iou_metric: 0.8010
Epoch 9/10
9528/9528 [==============================] - 34s 4ms/step - loss: 3.8350 - acc: 0.9949 - iou_metric: 0.8230
Epoch 10/10
9528/9528 [==============================] - 33s 3ms/step - loss: 3.5756 - acc: 0.9956 - iou_metric: 0.8232
1000/1000 [==============================] - 3s 3ms/step
evaluate results after [5.86476609992981, 0.995, 0.8262209377288818]
In just 10 epochs with a batch size of 64 the model achieves 82.6% on the test set for an IOU metric and 99.5% MSE loss!
Conclusion
I was really surprised by the performance of the network. It’s incredibly hard to get that good of generalization accuracy which is basically perfect. It’s a lot of fidgeting around with hyperparameters and hoping you guessed at the right anatomy of your model. I didn’t even need more than 5,000 labeled images either although I could have done some mutations on the data (rotation/flipping) to get around 25k images (not sure if that would have necessarily helped). Fascinating.
There is clearly a relationship between network depth and the ability to generalize a problem well. Something like ResNet-152 is really deep just because it has to compress a lot of information about the types of categorization it does, of which there are many categories but for something like classifying pools in very similar settings it naturally requires less layers. I believe to get a good model one should try tweaking the learning rate first, then the architecture of the network and if necessary add more data.
Back